
Ejecuta el escáner Find Untokenized Values de Atomize en cualquier archivo, página o selección de Figma y obtén inmediatamente una lista de todos los colores, espaciados, radios, métricas tipográficas, trazos, opacidades y efectos codificados que no están vinculados a una Variable - con un token sugerido para cada hallazgo y una exportación con un clic a JSON o XLSX. La deriva de tokens se acumula en todos los productos de larga trayectoria porque las Variables son opcionales por propiedad, por nodo, y la revisión visual no puede detectar un valor de espaciado que está 2 píxeles fuera de la escala. Un solo escaneo recorre trece categorías de propiedades, verifica la vinculación a través de boundVariables, agrupa los hallazgos por categoría y te da la ruta de capa y el valor bruto para que la limpieza se mapee directamente a un flujo de tickets.
Flujos relacionados: Encontrar valores no tokenizados en Figma, Guia de design tokens de Figma, y Auditoria de contraste en Figma.
Qué es un valor tokenizado en Figma
Un valor tokenizado en Figma es cualquier propiedad de capa vinculada a una Variable de Figma mediante el mapa boundVariables de ese nodo. El inspector puede seguir mostrando #0D99FF o 16px, pero Figma guarda un VARIABLE_ALIAS que apunta a un ID de variable - así los cambios de modo, las actualizaciones de biblioteca y la exportación de tokens se resuelven con nombres como color/primary/default o space/4 en lugar de un literal puntual. Los estilos que enrutan a Variables cuentan como tokenizados por la misma razón: lo que reporta la API es el alias, no el píxel calculado.
Tokenizado no significa «se ve acorde a la marca». Dos componentes pueden compartir los mismos rellenos y rellenos internos mientras solo uno está vinculado. Find Untokenized Values comprueba únicamente la vinculación: si un slot de propiedad no tiene alias en boundVariables, el valor no está tokenizado y entra en el informe aunque los píxeles coincidan con tu escala primitiva. Por eso los equipos combinan este escaneo con una estructura primitiva y semántica de tokens: deben alinearse nombres y vínculos, no solo la apariencia.
Qué significa realmente «no tokenizado»
Un valor no tokenizado es el caso contrario: una propiedad con un literal bruto y sin alias de Variable en ese slot. Un relleno #0D99FF y un relleno vinculado a color/primary/default se ven iguales en el lienzo; solo el vinculado responde a los modos, fluye en la exportación de tokens y hereda cambios aguas arriba. El escáner señala cada literal que expone la API - la clasificación es binaria y mecánica, por eso un pase automatizado es la única forma honesta de medir cobertura en miles de capas.
La deriva de tokens se acumula más rápido en las propiedades de espaciado y radio, no en el color - un hallazgo del escaneo de archivos reales de Figma con las herramientas de auditoría de Atomize. Las anulaciones de color se detectan en la revisión visual porque un rojo incorrecto es obvio. Un valor de espaciado 2px fuera de la escala de tokens pasa desapercibido durante meses - hasta que un desarrollador compara la especificación de diseño con la base de código y descubre que la brecha ha crecido hasta convertirse en un desajuste de múltiples propiedades. Los componentes con más probabilidades de llevar espaciado codificado son los que se construyeron antes de que se estableciera el sistema de tokens: barras de navegación, modales y elementos de formulario.
Tokenizado vs no tokenizado - un ejemplo rápido
El mismo frame de botón puede verse idéntico en dos archivos y seguir estando en estados completamente diferentes. El primero está completamente vinculado; el segundo tiene los mismos valores, escritos a mano. Atomize ignora el primero y reporta cada propiedad del segundo.
/* Tokenizado - vinculado a Variables */
relleno → color/primary/default (#0d99ff)
relleno/x → space/4 (16px)
relleno/y → space/3 (12px)
radio → radius/md (8px)
fuente/tamaño → text/body/md (14px)
/* No tokenizado - mismos valores, sin vinculación */
relleno = #0d99ff
relleno/x = 16px
relleno/y = 12px
radio = 8px
fuente/tamaño = 14pxPor qué aparecen valores no tokenizados en sistemas de diseño maduros
La deriva de tokens es un problema estructural, no un fallo de disciplina, y entender sus fuentes es el primer paso para controlarla. Las Variables en Figma son opcionales a nivel de propiedad - cada relleno, cada lado de relleno, cada radio debe vincularse individualmente, y ningún flujo de trabajo fuerza ese paso en el momento de editar; la unica forma de saber si la incorporacion realmente ocurrio en miles de capas es auditar el archivo, y un escaner lo hace en segundos. Al construir las herramientas de auditoria de Atomize con archivos de diseno reales, encontramos que la deriva entraba por cuatro vectores: frames de exploracion copiados en la pagina de componentes, tonos de correccion rapida unicos que nadie sube a la fuente, componentes construidos antes de que existieran sus definiciones de tokens y frames importados de bibliotecas no publicadas o externas.
De esos cuatro vectores de deriva, el responsable del mayor número de hallazgos en los escaneos de producción de Atomize no fueron los frames de exploración ni los casos únicos - fueron las barras de navegación, los modales y los elementos de formulario construidos antes de que se estableciera el sistema de tokens. Estos componentes pasaban cada revisión visual porque sus valores codificados coincidían con la paleta actual. Solo aparecían en los escaneos porque Atomize comprueba boundVariables en lugar de comparar valores de píxeles. En productos maduros, los componentes pre-token de este tipo suelen representar el 60-70% del total de hallazgos en un primer escaneo.
Qué comprueba el escáner de Atomize
El escáner de Atomize cubre trece categorías de propiedades en un solo paso, cerrando las brechas de auditoría que dejan abiertas las herramientas de solo color. La deriva de espaciado y radio es más difícil de detectar visualmente que la deriva de color - un valor de relleno 2 px fuera de la escala pasa la revisión de diseño durante meses - pero la mayoría de los plugins de la comunidad se detienen en los rellenos y trazos. Al trabajar con los archivos reales en la beta de Atomize, Vitalina encontró que las categorías de relleno y espacio producían rutinariamente más hallazgos que el color en los componentes construidos antes de que se estableciera el sistema de tokens. La tabla a continuación lista cada categoría verificada, las propiedades exactas de Figma inspeccionadas y el tipo de Variable con el que el escáner se corresponde.
Cobertura del escáner Find Untokenized Values
| Categoría | Propiedades de Figma verificadas | Tipo de Variable correspondiente |
|---|---|---|
| Relleno (color) | Pintura sólida, pintura con degradado | COLOR |
| Trazo (color) | Pintura de trazo | COLOR |
| Trazo (grosor) | strokeWeight, strokeTopWeight, strokeRightWeight, strokeBottomWeight, strokeLeftWeight | FLOAT |
| Radio de esquina | cornerRadius y radios por esquina | FLOAT |
| Relleno | paddingTop, paddingRight, paddingBottom, paddingLeft | FLOAT |
| Espacio | itemSpacing | FLOAT |
| Margen | counterAxisSpacing | FLOAT |
| Opacidad | opacity | FLOAT |
| Efectos | Sombra exterior, sombra interior, desenfoque de capa, desenfoque de fondo | COLOR / FLOAT |
| Familia tipográfica | fontFamily, fontName | STRING |
| Tamaño de fuente | fontSize | FLOAT |
| Peso de fuente | fontStyle, fontWeight | STRING / FLOAT |
| Altura de línea | lineHeight | FLOAT |
Si hasta ahora solo has construido una capa primitiva - lo cual está bien para sistemas en etapas tempranas - el escáner aún encuentra coincidencias cuando los valores brutos se alinean con las variables primitivas. Para un resultado más completo, combina esta auditoría con una estructura de tokens primitivos y semánticos saludable para que las sugerencias apunten a los nombres que realmente quieres que los componentes vinculen.
Cómo funciona el escaneo por dentro
El escáner opera como un recorrido en vivo del árbol de nodos de Figma, no como una instantánea en caché, lo que significa que refleja el estado exacto de vinculación de cada nodo en el momento en que lo ejecutas. Esto importa porque el inspector de Figma muestra valores calculados - no distingue a simple vista una Variable vinculada de un literal escrito. En cada nodo, el escáner lee tanto el valor de la propiedad como su entrada boundVariables, marca la propiedad como tokenizada solo si hay un VARIABLE_ALIAS presente y emite un hallazgo en caso contrario; el control se cede cada veinte nodos para que un archivo de 50.000 capas permanezca responsive durante todo el proceso. Comprender este pipeline explica por qué los resultados son deterministas y por qué un nuevo escaneo después de vincular un valor elimina ese hallazgo inmediatamente.
Recorrido del árbol de nodos
El walker es iterativo y basado en pila, lo que importa para los archivos grandes donde un descenso recursivo agotaría la pila de llamadas. Un pequeño objeto de contexto viaja con cada nodo para que las reglas posteriores puedan saber cosas como «estamos dentro de un componente de icono» o «esta rama es un banner» - útil para omitir las comprobaciones de espaciado irrelevantes en grupos de vectores internos.
Verificación de la vinculación mediante boundVariables
Cada propiedad tiene una clave conocida en boundVariables. Los rellenos usan un array, el relleno usa una entrada por lado, la altura de línea tiene su propio espacio. El escáner lee el ID del alias al que apunta la propiedad, y solo cuando no hay ningún alias registra un elemento no tokenizado. Las referencias de estilo vinculadas también se tratan como tokenizadas, ya que el propio estilo puede enrutarse a través de Variables.
Tokens sugeridos
Siempre que es posible, el informe no solo dice «esto está codificado» - nombra el token que probablemente querías. Atomize carga todas las colecciones de variables locales, sigue las cadenas de alias hasta llegar a un literal y construye dos mapas de búsqueda: uno del valor hex a la variable de color, otro del valor numérico a la variable numérica. Cuando aparece un #030712 codificado en un relleno, el informe sugiere text/primary si tu biblioteca lo define; cuando aparece un 8 como radio de esquina, sugiere radius/md. La sugerencia es una pista, no una acción automática - tú sigues controlando lo que se vincula.
Tres alcances de escaneo - Selection, Page, File
Elegir el alcance de escaneo correcto es el factor más importante en la relación señal-ruido del informe. Un escaneo File en un archivo de trabajo activo mostrará cientos de hallazgos en progreso junto con la deriva real, diluyendo los elementos accionables; un escaneo Selection en un componente terminado da un resultado limpio y rápido. Vitalina adoptó un ritmo de tres alcances durante el desarrollo de Atomize: Selection como comprobación continua mientras se itera, Page antes de las entregas de revisión de diseño, y File como puerta dura antes de cada publicación de biblioteca. Adapta el alcance al momento de tu flujo de trabajo y el informe seguirá siendo útil en lugar de abrumador.
Comparación de los tres alcances de escaneo
| Alcance | Qué recorre | Mejor para | Tiempo de escaneo típico |
|---|---|---|---|
| Selection | Solo los nodos seleccionados en la página actual | Auditar un componente antes de fusionarlo | Menos de 2 segundos |
| Page | Todos los nodos de nivel superior en la página actual | Revisar una pantalla, conjunto de frames o área de trabajo | 1-10 segundos |
| File | Todos los nodos de nivel superior en todas las páginas | Auditorías previas a la publicación y mantenimiento del sistema de diseño | 5-60 segundos según el tamaño |
En archivos de larga trayectoria, el alcance File puede producir miles de hallazgos en la primera ejecución. Trata ese escaneo inicial como una línea base y presupuesta la limpieza en iteraciones en lugar de bloquear el trabajo en un único ticket prioritario.
Leer el informe y actuar sobre él
El informe está diseñado para llevarte directamente desde el hallazgo hasta la corrección sin salir de Figma. Cada fila muestra el nombre del nodo, su ruta de capa, la página en la que se encuentra, el valor bruto y un token sugerido cuando coincide uno - hacer clic en el nombre del nodo lo selecciona en el lienzo y cambia automáticamente a la página correcta. Ese comportamiento de salto al nodo importa en archivos grandes donde un hallazgo en la página 7 requeriría de otra manera una búsqueda manual a través del panel de capas. Trabaja el informe categoría por categoría, usa Skip para reconocer los casos únicos intencionales, luego vuelve a escanear para confirmar que la vinculación aterrizó correctamente.
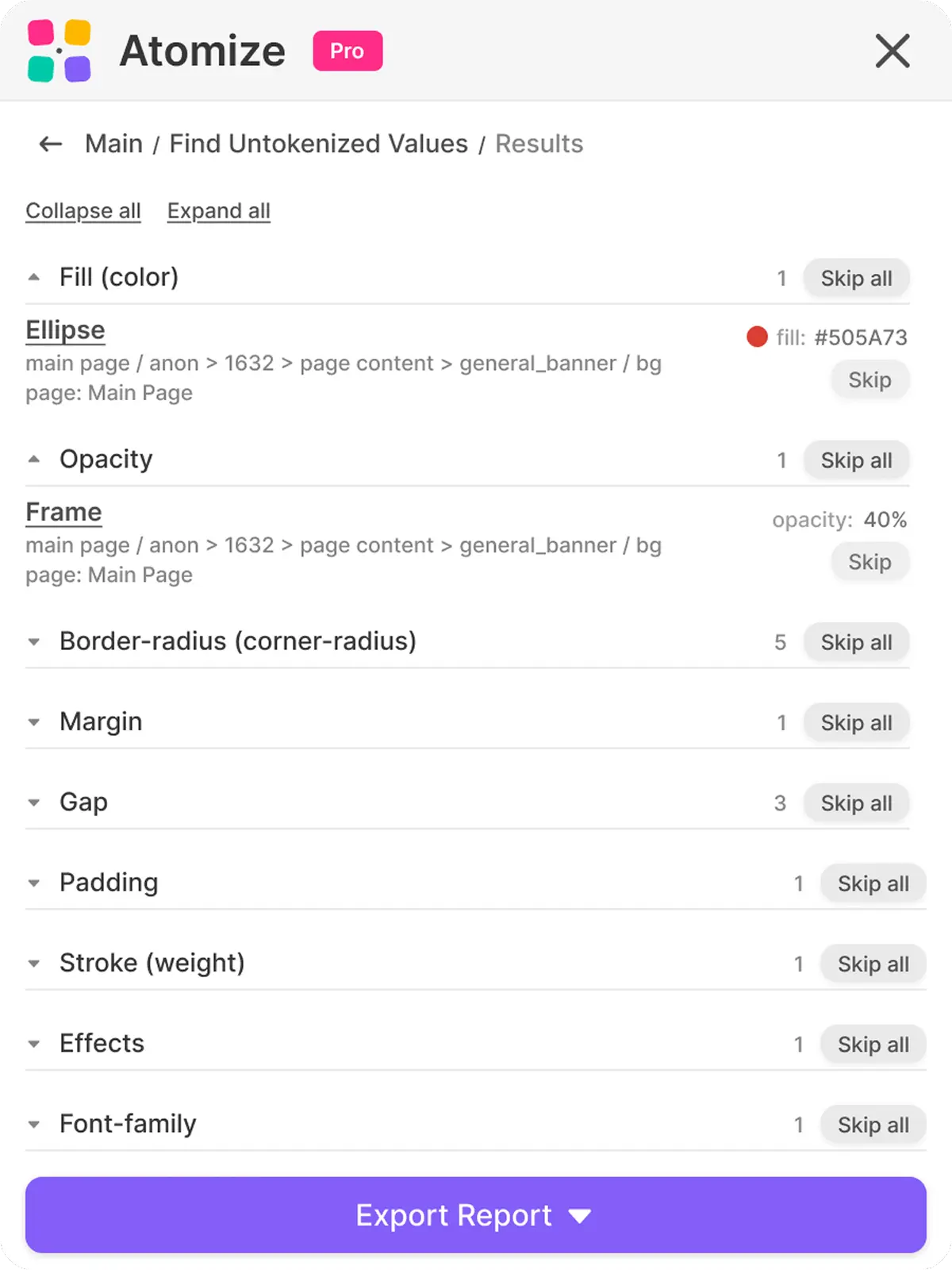
Acciones por elemento
- Haz clic en el nombre del nodo para ir a él en el lienzo
- Omite un elemento para eliminarlo de la lista visible sin eliminar el hallazgo
- Restaura un elemento omitido si cambias de opinión
- Colapsa o expande grupos enteros cuando una categoría domina el informe
Skip y Restore
Skip es local al informe actual - no edita el archivo ni las variables. Úsalo para reconocer los casos «este es intencionalmente bruto», como una imagen de marketing con un degradado específico de la marca, sin perder el rastro de ellos. Skip all y Restore all actúan en un grupo entero, que es la forma más rápida de hacer el triaje cuando una sola categoría domina el ruido.
Exportar a JSON o XLSX
Cuando quieras rastrear la limpieza fuera de Figma, exporta el informe. JSON es conveniente para herramientas y dashboards; XLSX es más amigable para la revisión de design-ops con un interesado no técnico. La forma exportada refleja lo que muestra el panel, con una fila por hallazgo.
{
"project": "Atomize Web",
"fileKey": "abc123",
"totalChecked": 4127,
"items": [
{
"nodeId": "1234:5678",
"nodeName": "Button / Primary",
"path": "Components / Buttons",
"page": "Library",
"property": "fill",
"rawValue": "#0d99ff",
"suggestedToken": "color/primary/default"
},
{
"nodeId": "1234:5680",
"nodeName": "Button / Primary",
"path": "Components / Buttons",
"page": "Library",
"property": "paddingLeft",
"rawValue": "16px",
"suggestedToken": "space/4"
}
]
}Find Untokenized Values vs otros plugins de auditoría de Figma
El escáner de Atomize es la única herramienta en la comunidad actual de Figma que cubre las cinco dimensiones de auditoría - color, espaciado, tipografía, efectos y sugerencias de tokens - con exportación en un solo paso. La mayoría de las alternativas manejan bien los rellenos y trazos pero se detienen ahí, dejando la deriva de espaciado y tipografía invisible a menos que ejecutes un segundo plugin. En las auditorías de archivos reales que realizó Vitalina al construir Atomize, las categorías que omiten esas herramientas - relleno, espacio, tamaño de fuente, altura de línea - eran precisamente donde vivían las mayores acumulaciones de deriva en los productos maduros. Para configuraciones nativas de Variables de Figma, la brecha de cobertura hace que un flujo de trabajo con múltiples herramientas sea impracticable; la tabla a continuación mapea lo que cada plugin verifica realmente.
Atomize Find Untokenized Values vs otros plugins de auditoría de Figma
| Plugin | Auditoría de color | Auditoría de espaciado / radio | Auditoría tipográfica | Auditoría de efectos | Sugerencias de tokens | Exportación |
|---|---|---|---|---|---|---|
| Atomize - Find Untokenized Values | Sí | Sí | Sí | Sí | Sí | JSON, XLSX |
| TokenOps | Sí | Sí | Parcial | Parcial | No | JSON |
| Relinky | Sí | Sí | Parcial | No | Parcial | No |
| Figxed Design System Audit | Sí | Sí | No | No | No | No |
| Design Token Checker | No | Sí | No | No | No | No |
Si vives en Tokens Studio, el Tokens Studio Tree Inspector sigue siendo útil específicamente para el flujo de trabajo de documentos de Tokens Studio. Para configuraciones nativas de Variables de Figma, Atomize cubre más categorías de propiedades en un solo paso y es el único de la lista que exporta tanto JSON como XLSX. Combínalo con un paso de exportación de tokens de tu flujo de trabajo de plugins de Figma para cerrar el ciclo hacia el código.
Mejores prácticas para mantener alta la cobertura
La cobertura de tokens solo mejora de forma duradera cuando el escaneo es parte del ritual de publicación, no una limpieza única. Una sola auditoría revela la deuda pendiente; no detiene la próxima ronda de deriva, porque la causa raíz - la incorporación opcional por propiedad sin una puerta - persiste. Los equipos que Vitalina observó que ejecutaban el escáner con regularidad detectaron las regresiones dentro del ciclo de iteración en lugar de en la retrospectiva post-publicación, lo que hizo que cada corrección fuera pequeña y obviamente contextual en lugar de grande y arqueológicamente confusa. Combina los escaneos regulares con las mejores prácticas del sistema de diseño más amplias que mantienen la estructura de Variables saludable y las sugerencias precisas.
Ejecútalo en cada rama de publicación
Antes de publicar una nueva versión de la biblioteca, ejecuta un escaneo de alcance File y resuelve primero las categorías de alto impacto - colores, luego relleno y espacio, luego tipografía. Los efectos y la opacidad tienden a producir los casos únicos más intencionales y son buenos candidatos para una pasada de Skip en lugar de una pasada de corrección.
Alcance por componente, no por página
Cuando los diseñadores están en mitad de la iteración, un escaneo Page puede ser demasiado ruidoso porque los frames de trabajo en progreso contaminan el informe. El alcance Selection en el componente activo te da un ciclo de retroalimentación más rápido y respeta el hecho de que la exploración siempre implica algunos valores codificados que se normalizarán más tarde.
Limitaciones que debes conocer antes de escanear
- Los degradados se reportan como
gradient-{type}en lugar de un hex, por lo que la coincidencia del token sugerido cae de vuelta a la revisión manual para los rellenos con degradado. - Los efectos se comprueban a nivel de vinculación de estilo, no por propiedad de sombra, por lo que una sombra parcialmente vinculada puede seguir siendo marcada como no tokenizada.
- El espaciado dentro de los grupos denominados
iconobannerse omite intencionalmente para evitar falsos positivos en los layouts de vectores internos. - El escáner recorre como máximo 100 niveles de profundidad - el anidamiento extremo más allá de eso es raro en la práctica pero vale la pena conocerlo.
- La vinculación automática desde el informe no está expuesta en la interfaz actual; el informe señala las sugerencias, tú haces la vinculación en el selector de variables de Figma.
Estas restricciones son límites de la API de Figma, no brechas en el diseño del escáner, y conocerlas evita malinterpretar el informe. La API del Plugin expone algunas vinculaciones como estilos de pintura y otras como alias directos de Variable, por lo que un escáner que las confunda produciría falsos negativos en los nodos vinculados a estilos. Vitalina mapeó cada restricción a su raíz en la API durante el desarrollo para que la tabla de cobertura anterior refleje lo que puede detectarse de forma fiable hoy. La documentación oficial de Variables de Figma es la referencia más fiable si quieres saber exactamente qué propiedad expone qué forma de vinculación.
Dónde encaja esto en un flujo de trabajo impulsado por tokens
Find Untokenized Values cierra el lado de entrada del pipeline de tokens - confirmando que los valores de diseño están realmente vinculados antes de llegar al código. Si tu equipo confunde este escaneo con Coverage Audit de Atomize, lee Coverage Audit vs Valores No Tokenizados para la diferencia entre puntuación de vinculación y lista de literales, y el orden de ejecución. Combínalo con una auditoría de contraste en Figma antes de publicar para que los fallos de accesibilidad no pasen cuando la vinculacion ya esta limpia. Vincular sin exportar sigue siendo una brecha, por eso los equipos que ejecutan el escáner consistentemente también necesitan el lado de salida: mover las Variables a JSON DTCG, propiedades CSS personalizadas o constantes TypeScript mediante un flujo de trabajo de paridad diseño-código. El W3C Design Tokens Community Group ha estado estandarizando el formato de intercambio en la especificación DTCG, y herramientas de construcción como Style Dictionary muestran el pipeline completo de extremo a extremo. Ejecuta la auditoría antes de cada paso de exportación y te aseguras de que el lado del diseño cumple el contrato antes de llegar al código.
Veredicto final - Find Untokenized Values
La cobertura de tokens no es medible por inspección - la deriva se oculta en propiedades que parecen correctas en el lienzo pero no llevan ninguna vinculación de Variable. Find Untokenized Values elimina ese punto ciego: recorre el árbol de nodos completo, verifica cada propiedad contra boundVariables, nombra el token que probablemente querías y exporta el resultado para que la limpieza pase a un flujo de tickets real en lugar de quedarse en la memoria del diseñador. Conviértelo en una puerta de publicación y el informe se convierte en una señal de regresión; ignóralo y la deriva se acumula silenciosamente hasta que la brecha entre diseño y código es demasiado grande para cerrarla en un sprint.


