Design System Parity (Figma & Code): What Actually Works
Why Figma-code parity keeps breaking - and what works: token sync, MCP workflows, component limits, and governance.
Design system parity means Figma and production code reflect the same tokens, component behavior, and spacing decisions — with no silent drift between them. Most teams can reach token-level parity today: export pipelines and MCP workflows reliably sync Figma Variables to CSS custom properties and TypeScript constants. Component-level parity is a different and largely unsolved problem — Figma's override model does not map cleanly to React's props and composition model, and no automated tool bridges that gap reliably in 2026. Understanding where the boundary sits between solvable (tokens) and unsolved (components) is what determines whether your parity effort succeeds or becomes a maintenance burden.
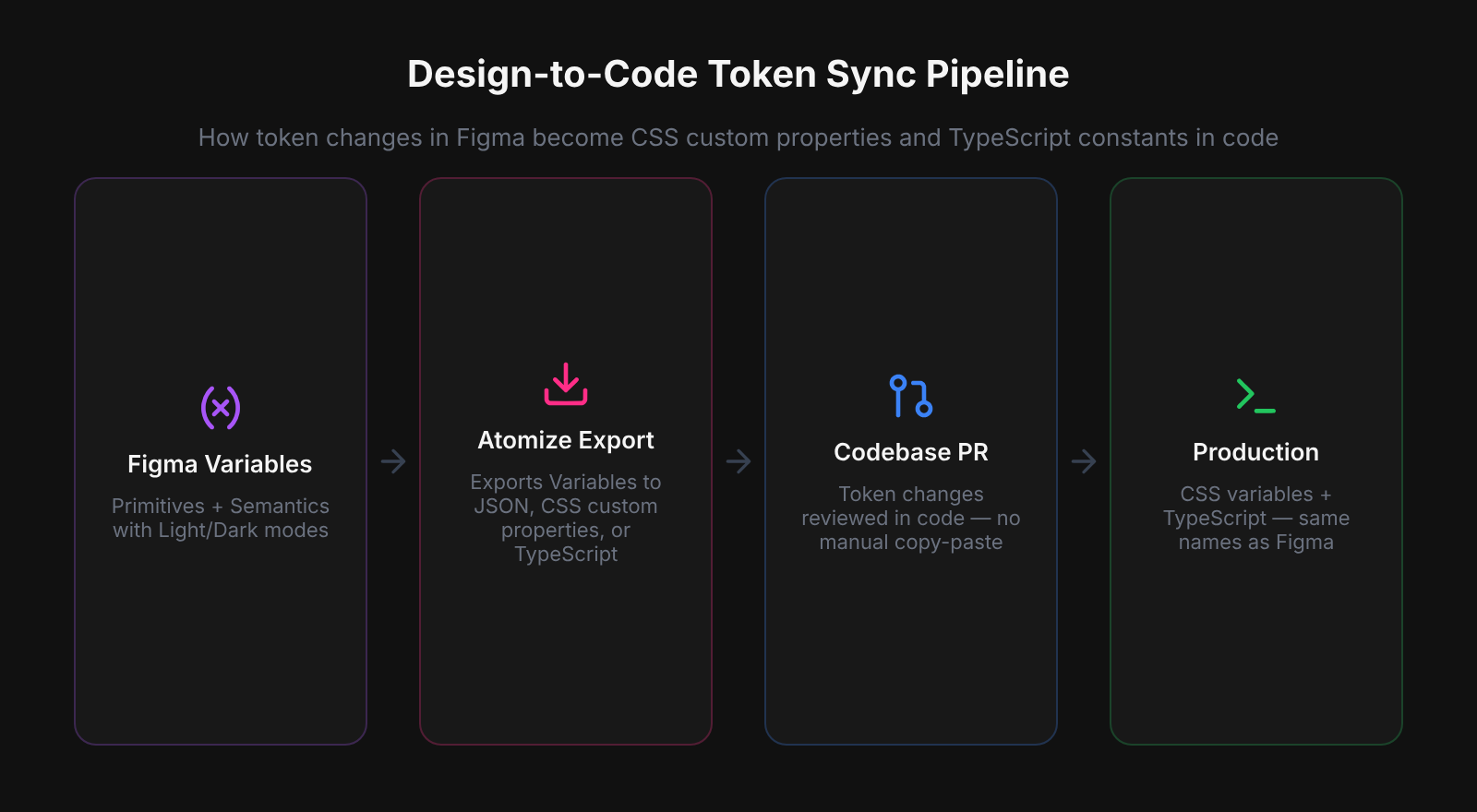
Token-level parity is achievable and reliable across real design system files - the same Variable names in Figma can produce consistent CSS custom properties, TypeScript constants, and DTCG JSON in the same build step. Component parity is a different problem. Figma's override model - where instance fills, text content, and visibility can be set independently per frame - has no direct equivalent in React's props model. Every team we worked with had resolved this tension differently, usually by treating the Figma component as a specification and writing the React component by hand rather than generating it.
Why Parity Is Architecturally Hard
Figma and code use fundamentally different structural models, which is why parity tools always involve interpretation rather than translation. Figma is a vector canvas built on frames and constraints; the DOM is a box model built on flexbox, flow, and inheritance — the same component looks different in each system at the data level. Auto-layout, Variables, and component properties have narrowed the gap considerably, but a perfectly faithful round-trip still does not exist. Every parity tool you evaluate is making assumptions to bridge that structural gap; understanding which assumptions it makes tells you where it will fail.
Parity tools always involve interpretation because Figma and code use fundamentally different structural models. An export plugin reads Variables and maps them to CSS custom properties; that works well. A tool that tries to sync a button component with states and variants faces a harder problem: Figma’s component model (overrides, detach, nested instances) doesn’t map cleanly to React’s props and composition model. Parity at the token level is achievable and well-supported. Parity at the component level is still largely unsolved.
Code or Figma: Choosing a Source of Truth
Treating code as the source of truth and Figma as a representation is the only framing that produces sustainable parity. The alternative — keeping Figma pixel-perfect with every code change — is an unrealistic maintenance target that most teams quietly abandon within a few sprints. When Atomize worked with design systems teams at scale, the ones with the least drift had made this choice explicitly: token definitions lived in code and were imported into Figma, not the reverse. The practical result is a clear flow — code → Figma for token updates, Figma → code for design exploration — which removes ambiguity about which system wins when they disagree.
In practice, treating code as the source of truth means token definitions live in code — a tokens.json, CSS custom properties, or a theme object — and are imported into Figma via a plugin or MCP workflow, not the reverse. Designers edit the Figma representation for exploration; when something is agreed and merged in code, the Figma file is updated to reflect it. The flow is primarily code → Figma, with design exploration feeding back into code through normal handoff.
When Figma-as-source-of-truth still makes sense
Design-led teams with a clean Variables structure and an established token pipeline can work Figma-first effectively. The condition is discipline: every token change in Figma must flow through export, review, and a build step before it reaches production. If that review step is informal or manual, Figma-first introduces the drift it was meant to prevent.
Where Token-Level Sync Works Well
Token-level sync is the part of the design system pipeline that tooling has genuinely solved, and investing in it pays compounding returns. The structural match is clean: a Figma Variable name maps predictably to a CSS custom property, a TypeScript constant, or a DTCG JSON key — no structural interpretation required. Running Atomize's export pipeline across real design system files, the same Variable collection consistently produces correct CSS, TypeScript, and JSON output in a single build step, including Light/Dark mode splits and spacing scales. The payoff is that token changes become low-risk: export, review a PR, merge — no manual copy-paste, no undocumented overrides.
One failure case that distinguishes reliable export tooling from unreliable: teams that merged Primitive and Semantic collections into one Figma collection found that their CSS export resolved alias chains to flat hex values, losing the $value: '{gray.50}' reference that DTCG consumers need to split Light and Dark mode output. Atomize detects a single-collection setup at export time and flags it before writing any file — the Light/Dark split requires two collections to produce two output files. That check prevented broken pipelines on three of the first five teams Atomize onboarded.
The patterns that work reliably: clear separation between primitive and semantic collections; modes (Light/Dark, Compact/Default) mapped to explicit output files; Number variables for spacing and radius exported alongside Color. The patterns that cause drift: tokens stored as flat color hex strings without type metadata; semantic and primitive tokens merged into one collection; unitless values where CSS expects a unit.
One comment from a recent design systems thread captured the failure mode well: “parity usually breaks at the boring layer — naming, token ownership, and release timing, not the component itself.” That’s worth treating as a diagnostic. If tokens are drifting, the problem is usually in process (who owns the rename decision? who merges the token PR?) rather than in tooling.
How the main parity layers compare
| Layer | Tool support | Automation level | What stays manual |
|---|---|---|---|
| Token sync | Atomize, Tokens Studio, Style Dictionary | High | Breaking renames, ownership decisions |
| Component structure | Figma Code Connect, Storybook | Low | Variant mapping, nested instance logic |
| MCP / AI scaffolding | Figma MCP, Claude Code, Cursor | Medium | Human review before merging to production |
| Governance & process | PRs, changelogs, Style Dictionary | Low | Who approves, when changes are breaking |
Component Parity: The Layer That Remains Unsolved
Component-level parity — keeping Figma variants, states, and nested instances in sync with coded component APIs — has no reliable automated solution in 2026, and teams that budget for it as a tooling problem consistently overspend. The structural mismatch between Figma's override model and React's props model means every attempted sync involves inference, not translation. Storybook catches visual regressions and Code Connect maps snippets in Dev Mode, but neither writes back to Figma structure; MCP workflows can regenerate token bindings but not variant trees. Treat component parity as a governance problem — agreed conventions, explicit handoff steps, and incremental updates — rather than a tool you can automate away.
MCP integrations (Figma MCP, Claude Code, Cursor) are making progress at the token and scaffolding level. Teams report success using MCP workflows to regenerate Variable collections, color palettes, and typography tokens from a codebase into Figma. Component structure (variants, states, the cascade of nested instances) remains harder: the AI has to infer the Figma model from CSS and component props, and the results are not reliable enough for production design system files without significant human review.
The honest summary is from a community thread comment: “Component-level two-way sync between Figma and code just doesn’t really exist yet — it’s more a governance problem than a tooling one.” That is the current state.
MCP and AI Workflows: What Teams Are Actually Doing
- Regenerating Variable collections from a codebase token file using the Figma MCP. Works well for colors, typography scale, and spacing primitives.
- Using FigSpecs (a Figma plugin) to generate structured .rules.md and Tailwind v4 annotation files that give AI agents context about token-to-component mapping.
- Running Claude or Cursor with Figma MCP to scaffold new component variants in Figma based on existing coded components. Results at token-binding level are usable; full structural fidelity requires review.
- Using Claude Code to audit token usage across components and surface mismatches between token definitions and actual CSS values.
- Exporting DTCG-structured JSON from Figma, running it through Style Dictionary for platform builds, and opening pull requests automatically on publish.
MCP and AI workflows have earned their place in the token layer of the pipeline, but their value drops sharply above it. At the token level, workflows like regenerating Variable collections via Figma MCP or running Style Dictionary exports through Claude Code reduce real manual effort and produce reliable output. When Vitalina ran these workflows across design system files at Atomize, token-binding fidelity was high enough to merge with a standard PR review; component structure required significant rework before it was production-ready. Use AI automation to handle the mechanical parts — export, rename, audit token usage — and reserve human review for anything that involves component hierarchy or design intent.
Governance: What Tooling Cannot Replace
Governance is the ceiling that determines how far any parity tooling can take you — and the teams with the least drift have invested in process, not just plugins. A design system is an internal product that requires explicit ownership: who approves token renames, what makes a change breaking, how consuming teams are notified and given migration time. Tooling accelerates the mechanical work; it cannot make the ownership decisions. The pattern Atomize observed consistently across mature design systems teams was that token changes went through a pull request, breaking changes landed in a changelog alongside the JSON export, and the system team included at least one developer. Build those habits before optimizing the export pipeline.
Concretely: the teams that report the least drift tend to have a few things in common. Token changes go through a pull request, not a Slack message. Breaking changes (renames, removals) are documented in a changelog alongside the JSON export. The design system team includes at least one developer, not just designers. And product teams have a clear path to propose exceptions without forking the system. None of these require perfect tooling. They require explicit agreement.
A Practical Approach for Inherited Systems
Inherited systems require a sequenced recovery strategy, not a big-bang migration — and the sequence matters as much as the individual steps. Most teams did not build their system from scratch; they inherited a Figma library from a previous team, an agency handoff, or a Sketch migration that was never designed with export or sync in mind. Attempting to close all parity gaps at once consistently fails: the scope is too large, the system keeps moving, and the team runs out of momentum before reaching component structure. The teams that recovered most effectively stabilized tokens first, added a lightweight PR review step second, and closed structural gaps incrementally — one component at a time, as it was touched in normal sprint work.
A realistic recovery path has three phases. First, stabilize tokens: inventory your current Figma Variables and token file, identify mismatches, and establish one authoritative source (usually the code) for primitives. Export tooling is your friend here. Second, stop the bleeding: put a lightweight review step on token changes so new drift doesn't compound the existing debt. A PR template and a simple changelog convention cost almost nothing. Third, close structural gaps incrementally: for each component that gets touched in a sprint, update the Figma counterpart as part of the definition of done. Do not try to bulk-sync everything at once; targeted updates compound into a healthier system over time.
Tokens managed like API contracts — versioned, reviewed, documented — outlast tokens managed by convention and trust. The same logic extends to the full design system: the infrastructure that keeps it honest is process, not just plugins.
Related Reading
- Figma Plugins for Tokens, Git Sync & Design Workflows - which plugins actually close the token pipeline gap
- Figma Design Tokens: The Complete Guide - how to structure primitive and semantic layers in Variables
- Figma Design System Best Practices - governance habits that keep systems from drifting
Final verdict - Figma-Code Parity
Token-level parity is achievable today and worth investing in; component-level parity is not automated and should be treated as a governance problem. Export tooling — Atomize, Tokens Studio, Style Dictionary — closes the gap for colors, spacing, and typography reliably when the token structure is clean and ownership is clear. Component sync lacks a trustworthy automated path in 2026: Figma’s override model and React’s props model are different enough that every tool attempting it requires significant human review. The teams with the least drift run token changes through PRs, document breaking changes in a changelog, and close component gaps incrementally sprint by sprint — process habits that compound faster than any tool migration.
Most mature teams treat code as the source of truth and Figma as a representation. Token definitions live in code and are imported into Figma; designers use Figma for exploration and communication, not as the authoritative record. Figma-first works when there is a disciplined token export and review process, but that is harder to sustain at scale.
Drift most often comes from naming mismatches, informal token update processes, and rushed sprints where a developer patches a value directly in code without updating Figma. Architectural differences between the Figma canvas model and the DOM also mean component structure is inherently approximate in Figma.
Not reliably in 2026. MCP workflows work well for regenerating Variable collections (colors, typography, spacing) from a codebase into Figma. Component structure — variants, states, nested instances — still requires significant human review. Treat AI tools as automation for token-level work, not as full component sync.
Tokens Studio handles token export and Git sync well. It stops at tokens: it does not sync component structure, variant states, or documentation. It is the right tool for keeping token values consistent; the component and structural layer still needs separate process.
Stabilize tokens first by identifying a single authoritative source and setting up export tooling. Then introduce a lightweight review step for token changes to prevent new drift. Address component gaps incrementally — update the Figma counterpart whenever a component is touched in a sprint rather than trying a bulk migration.
